
Hi, I am Satwant, presently pursuing my Masters in Data Science at the University of Southern California. I am a huge fan of Recommender Systems & Customer Profiling. My interests range from machine learning, Natural Language Processing, and extracting simple data rules from Black box complex models. I really like the way Machine Learning is improving Healthcare systems.
I would be happy to connect with you to talk about Machine Learning, Deep Learning, Natural Language Processing or Data Science in general.
Key Areas of Interest: Fraud & Error Reduction in UHC Insurance Payments Platform
1. Designed multiple preditive & Inferential models aimed at identifying fraud and error patterns in highly complex insurance claims data with billions of records flowing in every year
2. Shared Data Insights with Business stakeholders to enable process optimization and Audit time reduction
3. Achieved overall 7% reduction in FPR for Payment Integrity models after deploying a suite of models
4. Helped Business Intelligence team setup several dashboards for my projects & enabed automated projects valuation by establishing relevant KPIs on dashboards
Key Areas of Interest:Consumer Experience Improvement
1. Worked on several initiatives aimed at improving overall consumer experience with UHG
2. Deployed Repeat call prediction reduction model after mining key reasons for repeat calls.
3. Identified key reasons why consumers would atrite and setup a alternative product recommendation engine
4. Setup a NLP to Data Visualization Web App for helping our Leadership extract key KPIs using natural language queries on UI
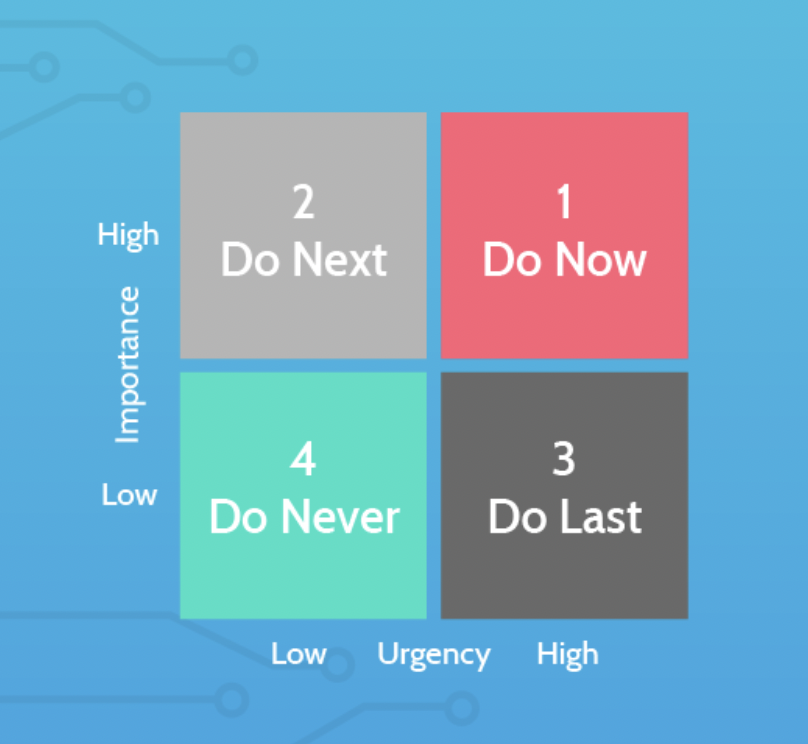
1. Built a Binary Classification GBM Model with 92% Precision using H2o Hadoop Cluster
2. Setup a monthly Refresh process for recalculating lookback features for Risk & Entropy for capturing seasonal trends
3. Along side predictive model, identified several high level error patterns with high TPR and deployed RPAs for those categories.
4. Orchestrated Tableau based Reporting Dashboard which captures both Model Performance in operational setting & also generates financial reports.
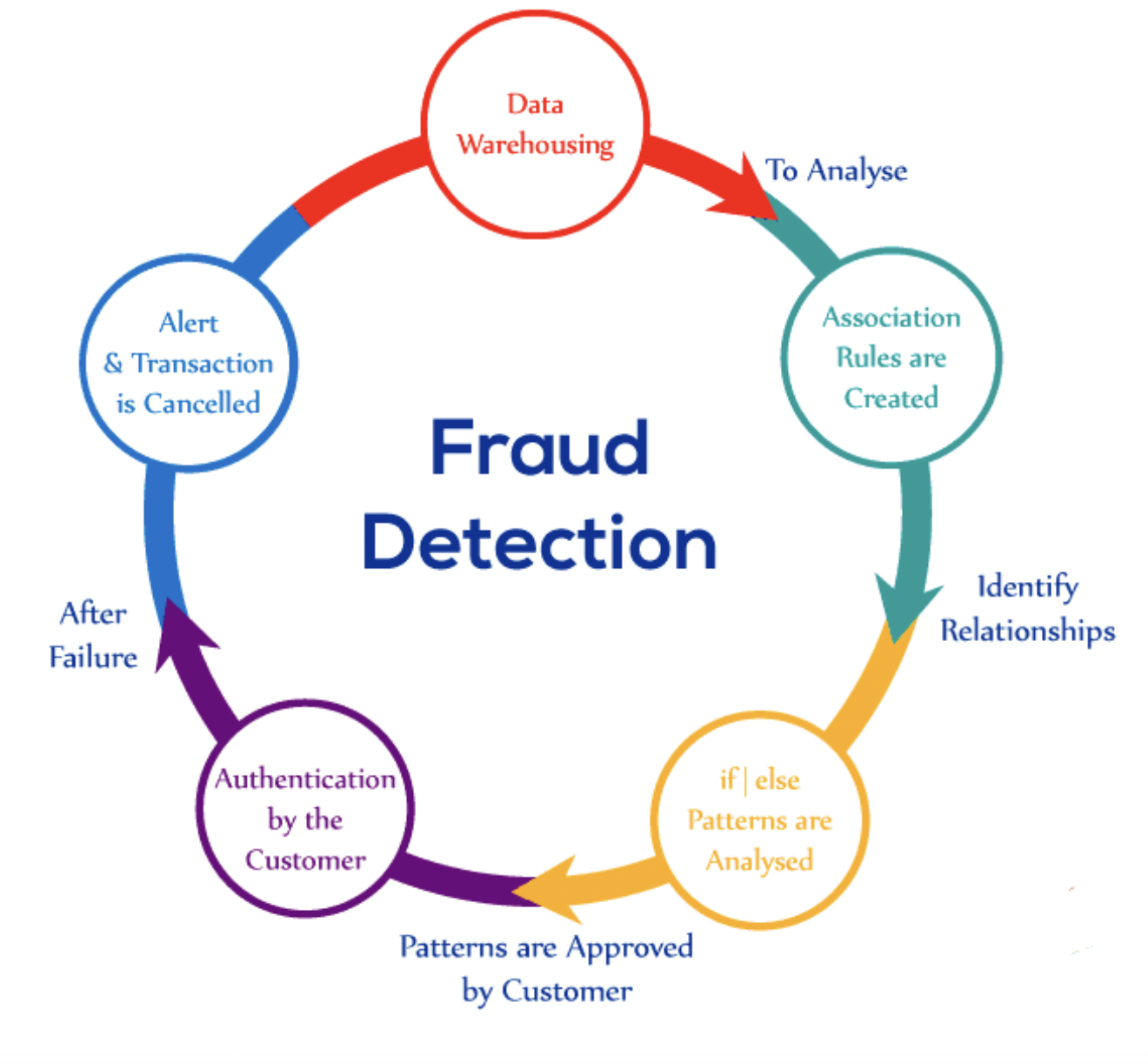
1. First of all, I tried implementing Sequence model for predicting Future ICD10 Codes for indiviual patients using their historical ICD10 Vectors
2. Results were not promising, I resorted to leveraging Optum Clinical bert Model for calculating Similarity between different ICD 10 codes basis their description.
3. Based on arrival results, I prepared my own word embeddings for 30k ICD10 codes. Then I estimated the TFIDF scores for each ICD10-ICD10 pair by leveraging 300B claim lines where I could generalize the Doc-Item relationship.
4. Once my feature space was ready, I was able to design a powerful classifier for predicting Clinical Fraud.
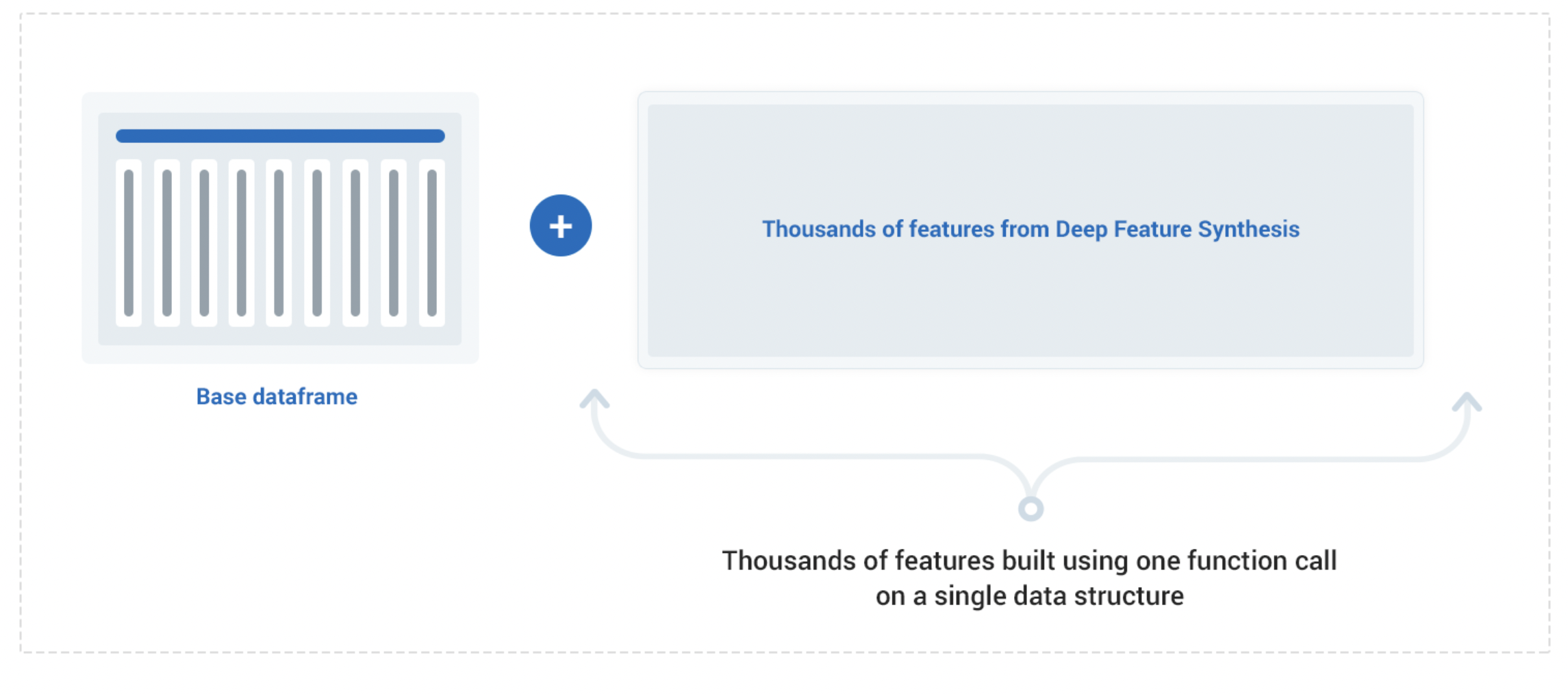
1. Most of the time during Data preparation goes into performing EDA and writting Feature Engineering Codes in Tabular Dataset Projects
2. Based on most commonly used features in Risk Modeling like Entropy, Lookback, Risk and Severity Risk, prepared a PySpark based FE Package.
3. By writting hardly 4-5 lines of code in PySpark, Entire Analytical Dataset can be prepared ready to be fed into Model Grid

1. Identified high churn rate Insurance plans in texas region and shortlisted top reasons for attrition.
2. Using Customer Profiling and collaborative Filtering based Recommendation System, Proposed alterate plans to high churn prone customers.
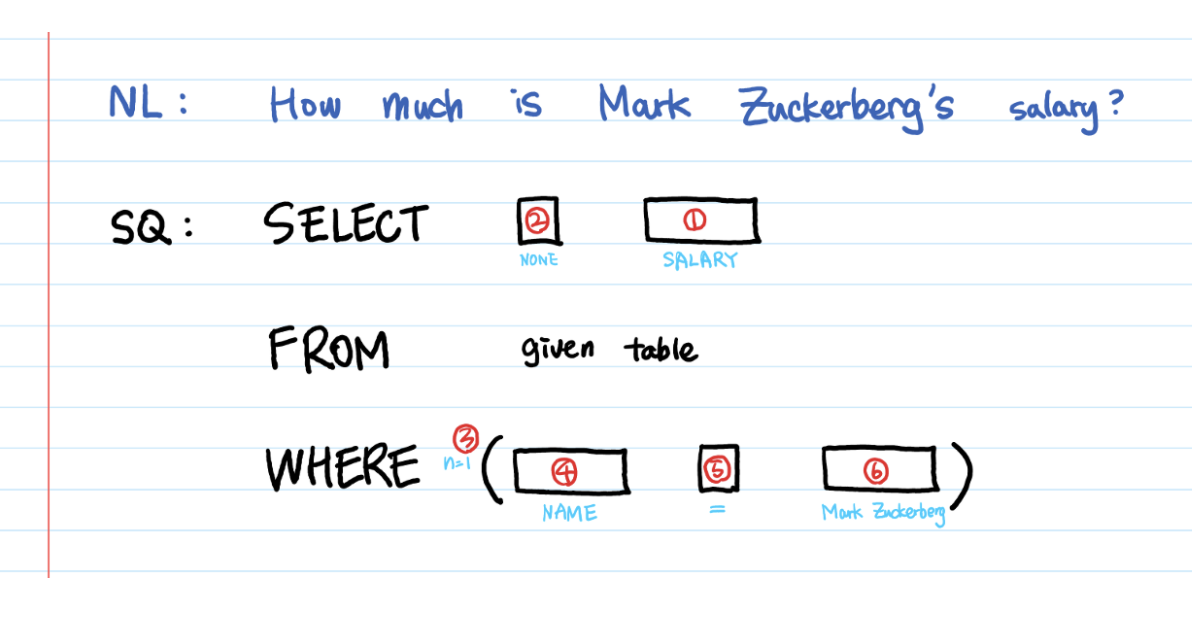
1. Delivered a simple yet powerful Natural Language to SQL Query generator and Visualization UI
2. Enabled Senior Leadership to use this UI for simple Data Querying by means of natural langauge where responses were in tabular form along with desired Visualization.
I had written this Blog during Covid-19 Lockdown in India when I was helping a bunch of Under Grad Students during their Job Search as their offers were rescinded.
View Blog
This blog aims at explaining basics of Anomaly Detection.I was exploring opportunity in Transactions Data and tried H2o Isolation Forest for conduting several POCs and benchmarking against existing Fraud Modeling models we had built in past. Have fun reading it and do let me know if you have any comments.
View Blog
Feel free to refer this blog for basic spark concepts & operations including but not limited to data loading,processing & transformation.I was onboarding 2 Fresh Recruits into our team and wanted to ensure they learn the basics of Spark in a very simple yet effective manner.
View Blog
I refer to this article for almost all my data manipualtion and other aspects in Python like EDA, Data Modeling, Data Connections and basic Text Analytics.
View Blog